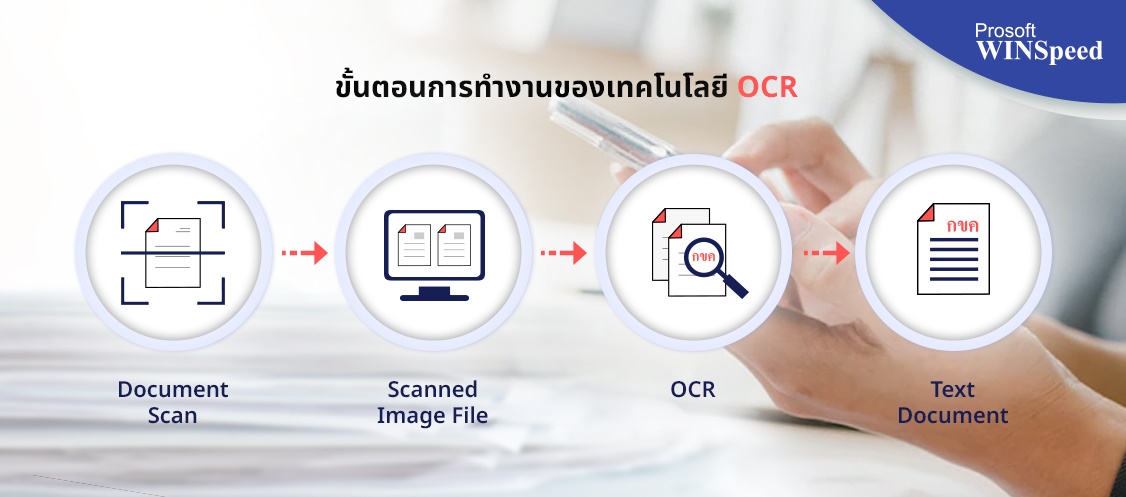
1. การรับภาพ ตัวสแกนจะอ่านเอกสารและแปลงเป็นข้อมูลไบนารี จากนั้นซอฟต์แวร์ OCR จะวิเคราะห์ภาพที่สแกนและระบุส่วนที่สว่างเป็นพื้นหลัง และส่วนที่มืดเป็นข้อความ
2. กระบวนการก่อนการประมวลผล ซอฟต์แวร์ OCR จะทำความสะอาดรูปภาพก่อน และลบข้อผิดพลาดออกเพื่อเตรียมรูปภาพสำหรับการอ่าน
3. การรู้จำข้อความ อัลกอริทึมหรือกระบวนการด้านซอฟต์แวร์ OCR หลักสองประเภทที่ซอฟต์แวร์ OCR ใช้ในการรู้จำข้อความเรียกว่าการจับคู่รูปแบบ (Pattern Recognition) และการแยกลักษณะ (Feature Detection) - การจับคู่รูปแบบ (Pattern Recognition) เป็นการตรวจจับตัวอักษรในภาพรวม โดยการแยกภาพ อักขระที่เรียกว่ารูปอักษร และเปรียบเทียบกับรูปอักษรที่จัดเก็บไว้ในลักษณะเดียวกัน การรู้จำรูปแบบจะทำงานได้ก็ต่อเมื่อรูปอักษรที่จัดเก็บไว้มีแบบอักษรและมาตราส่วนใกล้เคียงกับรูปอักษรที่ใช้ เช่น ตัวอักษร A ระบบจะเปรียบเทียบรูปที่แสกนเข้ามาเทียบกับตัวอักษร A ที่อยู่ในระบบ หากมีลักษณะเดียวกัน ระบบจะระบุได้เลยว่านี่คือตัวอักษร A - การแยกลักษณะ (Feature Detection) การแยกลักษณะจะแบ่งหรือแยกย่อยรูปอักษรออกเป็น คุณสมบัติต่างๆ ได้อย่างละเอียด รวมถึงข้อความที่เป็นการเขียนด้วยลายมือ ระบบก็สามารถจำแนกได้ เช่น เส้น วงปิด ทิศทางของเส้น และจุดตัดของเส้น ความเอียงของตัวอักษร จากนั้นจึงใช้คุณสมบัติเหล่านี้เพื่อค้นหาคู่ที่เหมาะสมที่สุดหรือตำแหน่งข้างเคียงที่ใกล้ที่สุดในบรรดารูปอักษรต่างๆ ที่จัดเก็บไว้
4. กระบวนการหลังการประมวลผล หลังจากการวิเคราะห์ ระบบจะแปลงข้อมูลตัวอักษรที่แยกออกมาเป็นไฟล์ที่ใช้ระบบคอมพิวเตอร์ เช่น ไฟล์ PDF, Word, Excel